FwordCTF2k21 infrastructure
FwordCTF2k21
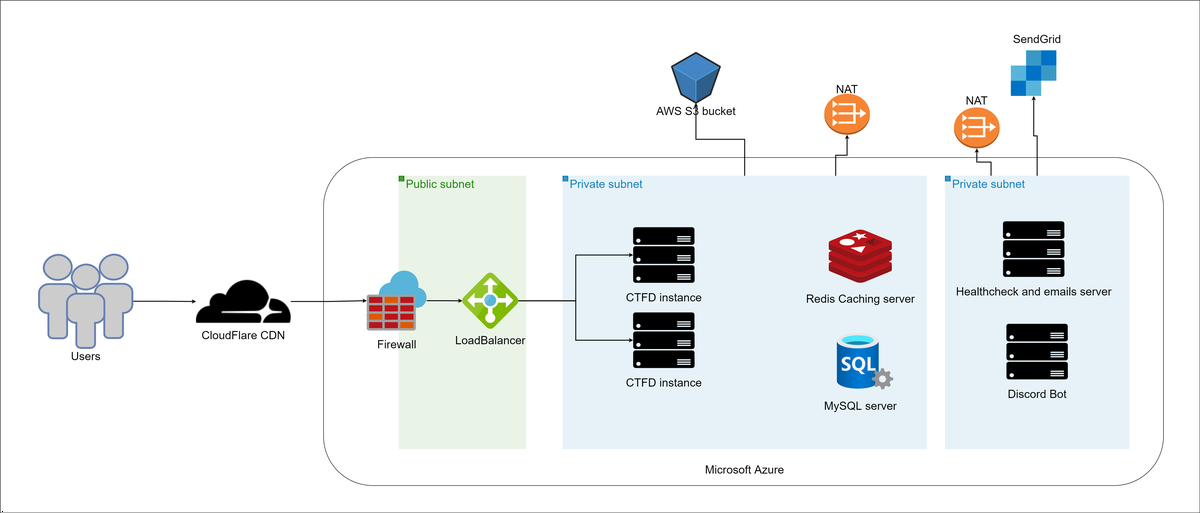 Image credit: Unsplash
Image credit: Unsplash{kind=link}
In the first article, we talked about the various automation scripts we used in FwordCTF 2k21, and in this one, we will be covering all the details about the infrastructure we worked with during the whole CTF. The CTF was awesome, it was an amazing experience, even better than the first edition even though it was stressful for the first 3 hours, because of a tiny issue that had a lot of damage we will talk about it later
So let’s start with some stats about our event. as we mentioned before, in this year’s edition we had 1925 registered users and 1001 teams
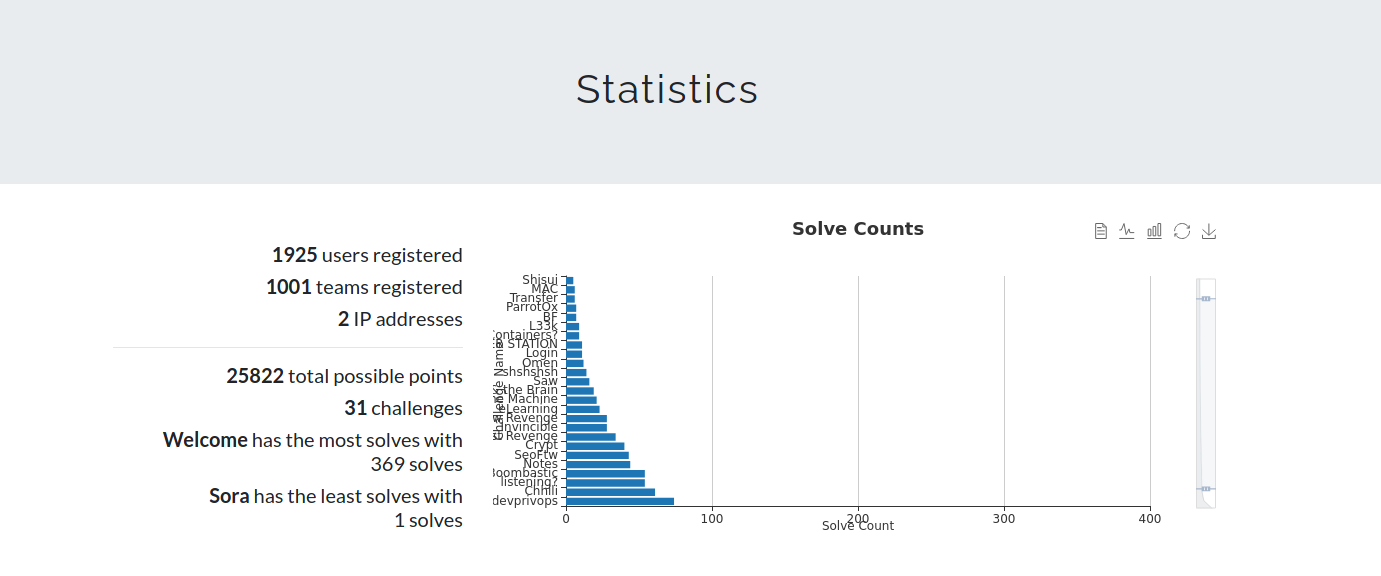 In addition to that we had a lot more traffic than the previous year and here are some stats from cloud flare:
In addition to that we had a lot more traffic than the previous year and here are some stats from cloud flare: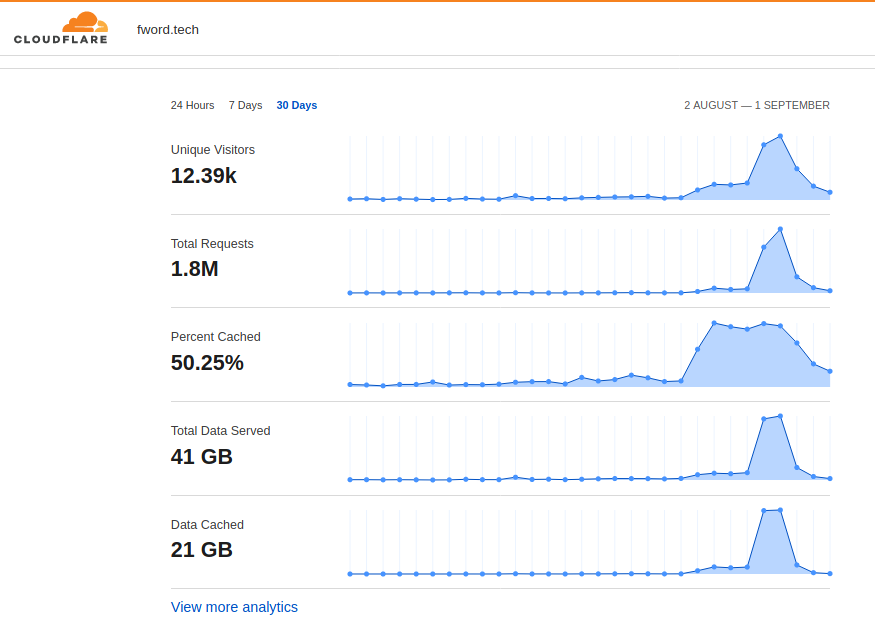
As you see the traffic was huge and the participants didn’t make it easy at all the DDOS attacks were remarkable xD thank god CloudFlare was in the rescue we forgot to take screenshots but we had around 40K threats on Cloudflare stats but as KAHLA said last year in his article:
“hackers can’t be hacked easily :p” Ahmed Belkahla Sep 22, 2020
So as I said a lot of users and heavy traffic needed a strong infrastructure to handle all that so will talk in detail about the architecture and the different components and services in it.
Summary
- The main infrastructure
- Hosting the tasks
- Management and monitoring
- The problems we faced
- Our plans for the next edition
- Conclusion
The main infrastructure
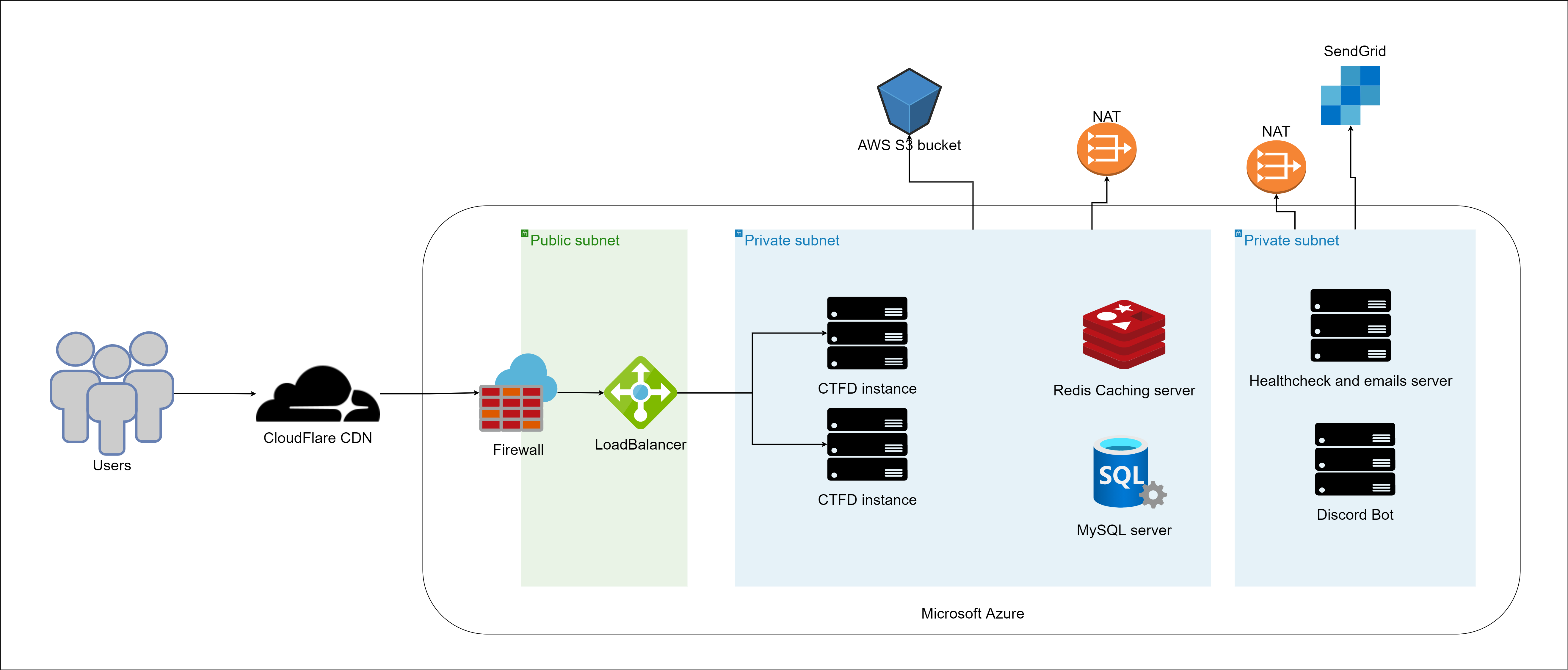 So in the schema above, it shows all the components of Fword CTF infrastructure and bellow are all the details:
So in the schema above, it shows all the components of Fword CTF infrastructure and bellow are all the details:
- Microsoft Azure as a cloud platform
- Servers: - 2 * CTFD Instance: Ubuntu Server 20.04 LTS - Gen2 (Standard E2s v3 - 2 vcpus, 16 GiB memory) : a docker swarm Master Node + 1 Worker node - Redis caching instance: Ubuntu Server 20.04 LTS - Gen2 (Standard_D2s_v3 - 2 vcpus, 8 GiB memory) - MySQL server: Ubuntu Server 20.04 LTS - Gen2 (Standard_D2s_v3 - 2 vcpus, 8 GiB memory) - 2 * Ubuntu servers for the automation scripts: Ubuntu Server 20.04 LTS - Gen2 (Standard_DS1_v2 - 1 vcpu, 3.5 GiB memory)
- Azure LoadBalancer
- CloudFlare
- AWS S3 bucket to serve the files to download.
- Sendgrid free account (25k free emails): We used Sendgrid for sending the certificates after the CTF.
Now let’s break down each component and why have we gone with that specific option.
For the cloud platform, we have gone with Microsoft Azure for one and only one reason.

Microsoft Azure was the only solution because we had the 100$ credit we get as students but we can’t deny it was easy to use and it had a lot of useful features. For the CTFd instances we initially wanted to go with 4*8GiB servers with 2 replicas in each node (you can read about how we used docker swarm in last year article) but due to Microsoft Azure for students limitation we only could have a total of 4 virtual cores per account and we needed the CTFd nodes to be in the same account so finally, we opted for 2 16GiB 2 cores servers with 4 replicas in each node and of course we needed Azure LoadBalancer to load the traffic between the two servers.
For the Redis caching server and the MySQL server we went with 2 core and 8GiB servers to make sure everything went smoothly.
Now for the discord bot and automation scripts we went for two 1 vcpu, 3.5 GiB, we know we could run them on our PC’s but having a good internet connection was a must and the speeds in the servers were awesome.
As you noticed at the beginning of the article we used CloudFlre cdn as it is free and easy to use nd it provided a lot of useful statistics and security measurements. For the static files storage, we used AWS S3 bucket the same as last year.
Now for SendGrid, we talked in detail about why we went with it in the automation article.
Hosting the tasks For the tasks we used 6 Azure VMs: Ubuntu Server 20.04 LTS - Gen2 (Standard E2s v3 - 2 vcpus, 16 GiB memory), and every tsks was in a separate docker container.
And for the deployment, we used the same scripts as last year’s edition.
For the tasks we used 6 Azure VMs: Ubuntu Server 20.04 LTS - Gen2 (Standard E2s v3 - 2 vcpus, 16 GiB memory), and every tsks was in a separate docker container.
And for the deployment, we used the same scripts as last year’s edition.
Management and monitoring
For the servers management, we used Termius because it’s awesome and made our life easier we had separate groups for the tasks servers and the infra servers
Main group:
Sub groups:
infra:
tasks:
Now for the servers monitoring as we talked about in the previous article we made our custom scripts to alert us if anything goes wrong but to be extra safe we used newRelic New Relic is a platform used for monitoring and you can customize how you show the data. It was awesome and features rich it alerted us when a server had a heavy load or if any problem accrued in addition we could always monitor the server stats like CPU and memory usage:
New Relic is a platform used for monitoring and you can customize how you show the data. It was awesome and features rich it alerted us when a server had a heavy load or if any problem accrued in addition we could always monitor the server stats like CPU and memory usage: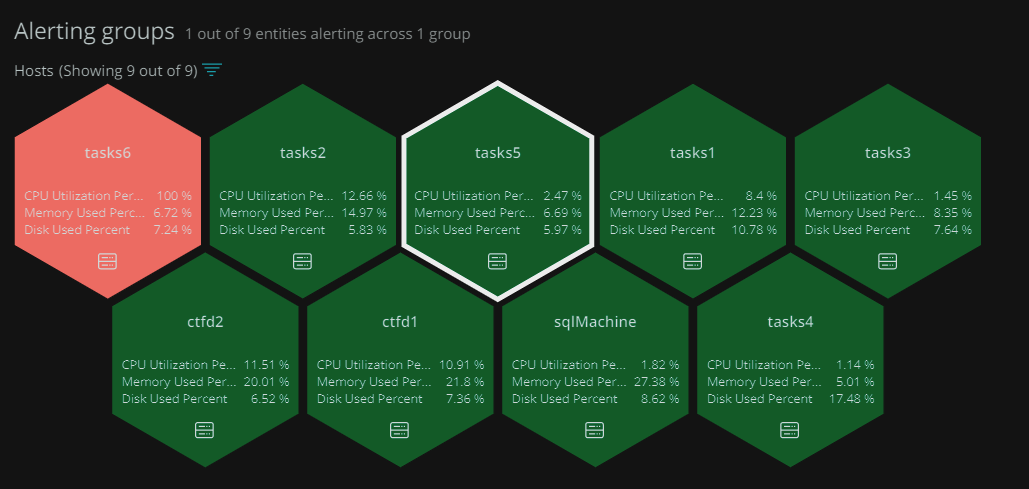
The problems we faced
In this year’s edition, the infrastructure was pretty much flawless. We had 0 downtime and everything thing went smooth except two pwn tasks that went down for a little while due to a heavy load from the participants but a simply restarted the docker containers and it went well. But the big issue we faced was CTFd. Our mistake was that we used the same theme as last year on an updated version of CTFd and it wasn’t compatible so the submit button didn’t work for the first couple of hours until we figured out the issue and changed the theme to the default one.
Our plans for the next edition
So, next year we plan to use a different platform than CTFd, as it has a lot of problems and it’s not the most efficient. Maybe we can develop our platform. for the automation scripts and bot, we plan to make an all-around bot that has all the needed features including tasks health checks and interacting with the participants and maybe also making the deployment of the task more automated so we take less time deploying the tasks and have time to test everything to avoid issues like we faced this edition. and finally, if we can we plan to use Terraform to deploy the old infrastructure.
Conclusion
Finally, we were happy with the result, it wasn’t flawless but it served us well and we got good feedback overall. Working on this project was a nice opportunity to learn more about deployment and cloud technologies. and we hope we can improve our skills to deliver a better result in the next edition.
Mohamed Arfaoui
Cyber Security Engineer | CyberSecurity Specialist @YOGOSHA
A cybersecurity enthusiast specialist in reverse engineering and malware analysis.